前言
最近,消息队列(Message Queue ,简称 MQ)越来越火。很多公司在用,很多人在用,其重要性不言而喻。
如果让你回答下面这些问题,你的心中是否有答案了呢?
- 为什么要用 MQ?
- 引入 MQ 会多出哪些问题?
- 如何解决这些问题?
本文将会一一为你解答,这些看似平常却很有意义的问题。
1. 传统模式有哪些痛点
痛点 1
有些复杂的业务系统,一次用户请求可能会同步调用 N 个系统的接口,需要等待所有的接口都返回才能真正的获取执行结果。
这种同步接口调用的方式总耗时比较长,非常影响用户体验。特别是在网络不稳定的情况下,极容易出现接口超时问题。
痛点 2
很多复杂的业务系统,一般都会拆分成多个子系统。以用户下单为例,请求会先通过订单系统,然后分别调用支付系统、库存系统、积分系统和物流系统。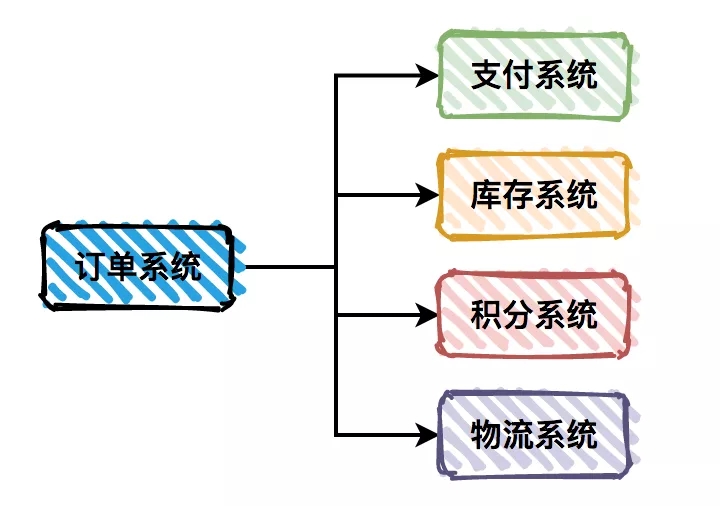
系统之间耦合性太高,如果调用的任何一个子系统出现异常,整个请求都会异常。对系统的稳定性非常不利。
痛点 3
为了吸引用户,有时候会搞一些活动,比如秒杀等。
如果用户少还好,不会影响系统的稳定性。但如果用户突增,一时间所有的请求都到数据库,可能会导致数据库无法承受这么大的压力,响应变慢或者直接挂掉。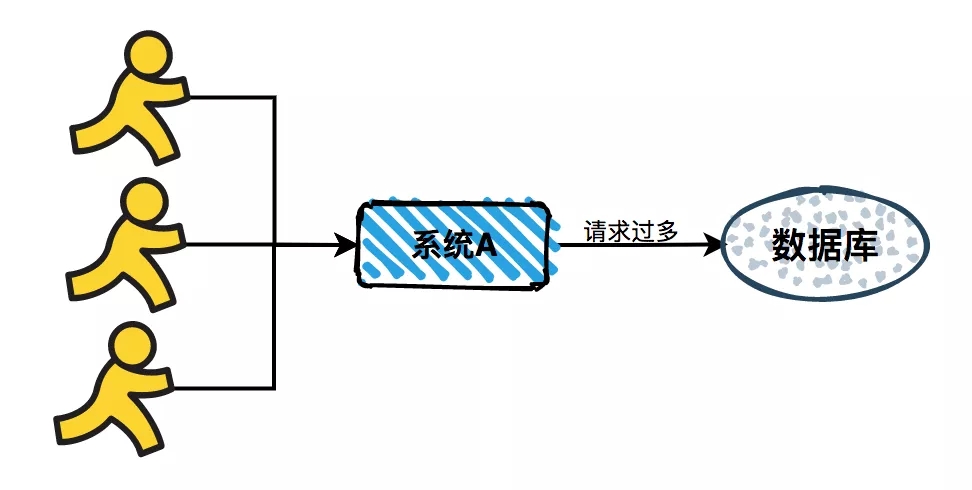
对于这种突然出现的请求峰值,无法保证系统的稳定性。
2. 为什么要用 MQ
对于上面传统模式的三类问题,使用 MQ 就能轻松解决。
2.1 异步
对于痛点 1 同步接口调用导致响应时间长的问题。使用 MQ 之后,将同步调用改成异步调用,能够显著减少系统响应时间。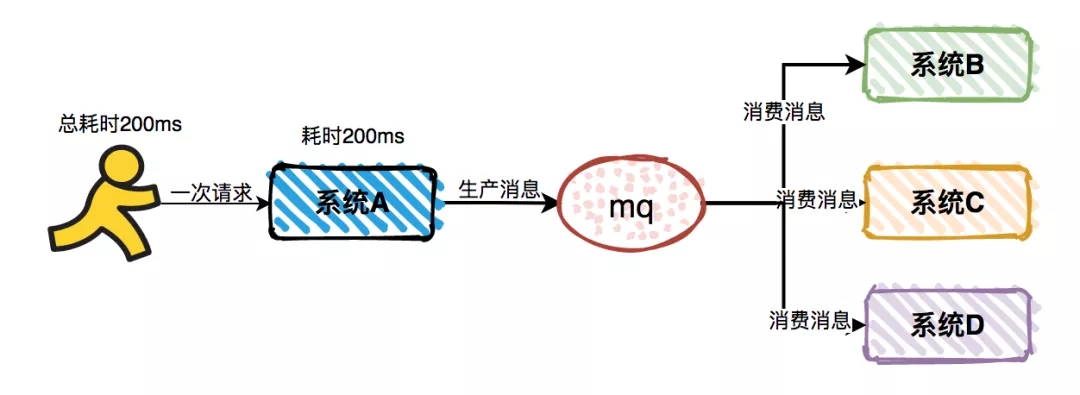
系统 A 作为消息的生产者,在完成本职工作后就能直接返回结果了。无需等待消息消费者的返回,它们最终会独立完成所有的业务功能。
这样能避免总耗时比较长,从而影响用户的体验的问题。
2.2 解耦
对于痛点 2 子系统间耦合性太大的问题,使用 MQ 之后,只需要依赖于 MQ。避免了各个子系统间的强依赖问题。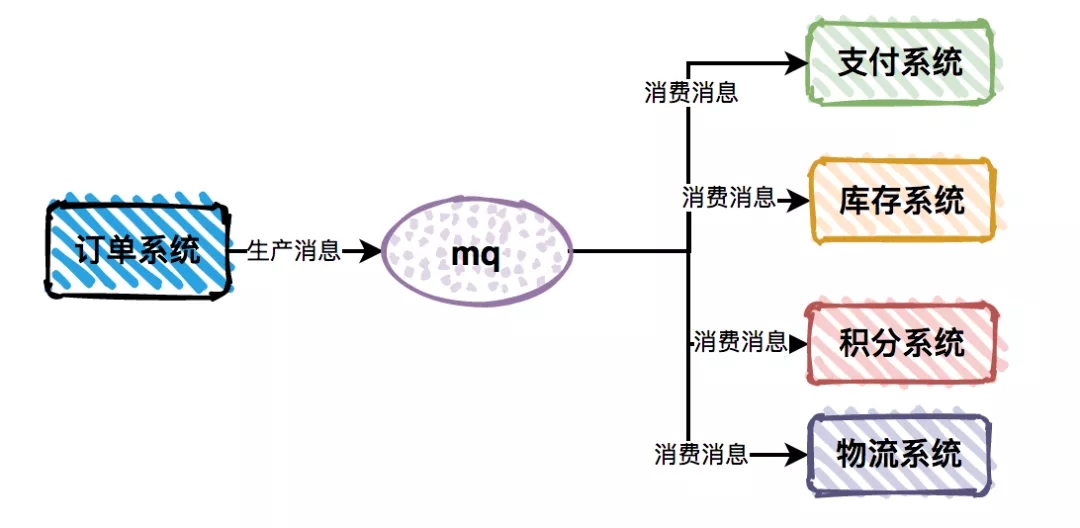
订单系统作为消息生产者,保证它自己没有异常即可,不会受到支付系统等业务子系统的异常影响。并且各个消费者业务子系统之间,也互不影响。
这样就把之前复杂的业务子系统的依赖关系,转换为只依赖于 MQ 的简单依赖,从而显著的降低了系统间的耦合度。
2.3 削峰
对于痛点 3,由于突然出现的请求峰值导致系统不稳定的问题。使用 MQ 后,能够起到削峰的作用。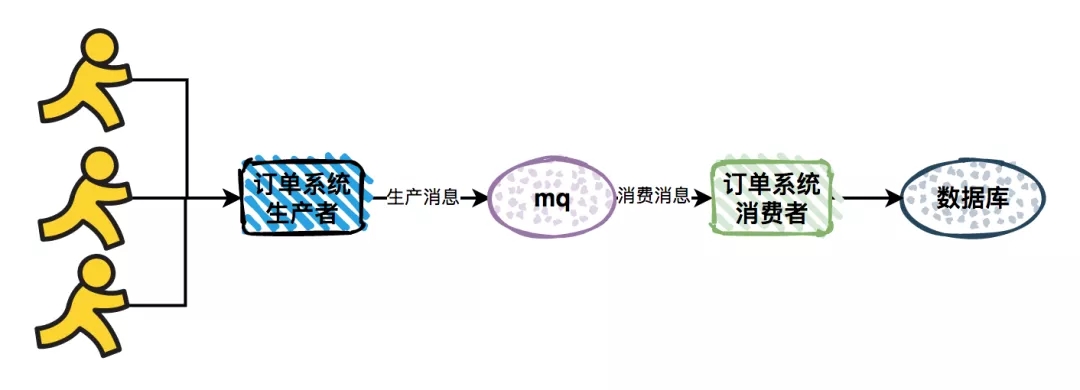
订单系统接收到用户请求之后,将请求直接发送到 MQ;
然后,订单消费者从 MQ 中消费消息,做写库操作;
当出现请求峰值的情况,由于消费者的消费能力有限,会按照自己的节奏来消费消息。多余请求不处理,保留在 MQ 的队列中,不会对系统的稳定性造成影响。
3. 引入 MQ 会多出哪些问题
引入 MQ 后让子系统间耦合性降低了,异步处理机制减少了系统的响应时间。同时能够有效的应对请求峰值问题,提升了系统的稳定性。
但是,引入 MQ 的同时也会带来一些问题。
3.1 重复消费问题
重复消费问题可以说是 MQ 中普遍存在的问题,不管你用哪种 MQ 都无法避免。
有哪些场景会出现重复的消息呢?
消息生产者产生了重复的消息;
Kafka 和 RocketMQ 的 offset 被回调了;
消息消费者确认失败;
消息消费者确认时超时;
业务系统主动发起重试。
如果重复消息不做正确的处理,会对业务造成很大的影响,产生重复数据或者导致数据异常,比如会员系统多开通了一个月的会员等。
3.2 数据一致性问题
很多时候,如果 MQ 的消费者业务处理异常,就会出现数据一致性问题。
举个例子,一个完整的业务流程是,下单成功之后送 100 个积分。下单写库成功了,但是消息消费者在送积分的时候失败了。这样就会造成数据不一致的情况,即该业务流程的部分数据写库了,另外一部分没有写库。
如果下单和送积分在同一个事务中,要么同时成功,要么同时失败。这样不会出现数据一致性问题的。
但由于跨系统调用,为了性能考虑一般不会使用强一致性的方案,而改成达成最终一致性即可。
3.3 消息丢失问题
同样消息丢失问题,也是 MQ 中普遍存在的问题,不管你用哪种 MQ 都无法避免。
有哪些场景会出现消息丢失问题呢?
生产者产生消息时,由于网络原因发送到 MQ 失败了;
MQ 服务器持久化,存储磁盘时出现异常;
Kafka 和 RocketMQ 的 offset 被回调时,略过了很多消息;
消费者刚读取消息,已经 ACK 确认,但业务还没处理完,服务就被重启了。
导致消息丢失问题的原因挺多的,生产者、MQ 服务器、消费者都有可能产生问题。我在这里就不一一列举了。
最终的结果会导致消费者无法正确的处理消息,而导致数据不一致的情况。
3.4 消息顺序问题
有些业务数据是有状态的,比如订单有下单、支付、完成、退货等状态。如果订单数据作为消息体,就会涉及顺序问题了。
例如消费者收到同一个订单的两条消息。第一条消息的状态是下单,第二条消息的状态是支付,这是没问题的。
但如果第一条消息的状态是支付,第二条消息的状态是下单就会有问题了。没有下单就先支付了?
消息顺序问题是一个非常棘手的问题,比如:
Kafka 同一个 partition 中能保证顺序,但是不同的 partition 无法保证顺序;
RabbitMQ的同一个 queue 能够保证顺序,但是如果多个消费者同一个 queue 也会有顺序问题。
如果消费者使用多线程消费消息,也无法保证顺序。
如果消费消息时同一个订单的多条消息中,中间的一条消息出现异常情况,顺序将会被打乱。
还有如果生产者发送到 MQ 中的路由规则,跟消费者不一样,也无法保证顺序。
3.5 消息堆积
如果消息消费者读取消息的速度,能够跟上消息生产者的节奏,那么整套 MQ 机制就能发挥最大作用。
但是很多时候,由于某些批处理或者其他原因,导致消费速度小于生产速度。这样会直接导致消息堆积问题,从而影响业务功能。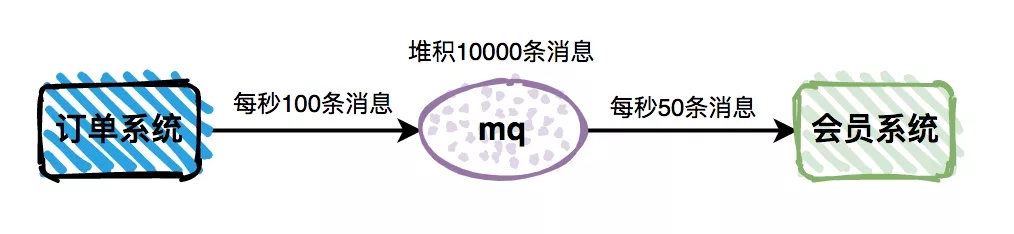
这里以下单开通会员为例,如果消息出现堆积会导致用户下单之后,很久之后才能变成会员。这种情况肯定会引起大量用户投诉。
3.6 系统复杂度提升
这里说的系统复杂度和系统耦合性是不一样的。
假设以前只有系统 A、系统 B 和系统 C 三个系统,引入 MQ 之后,除了需要关注前面三个系统之外,还需要关注 MQ 服务。需要关注的点越多,系统的复杂度越高。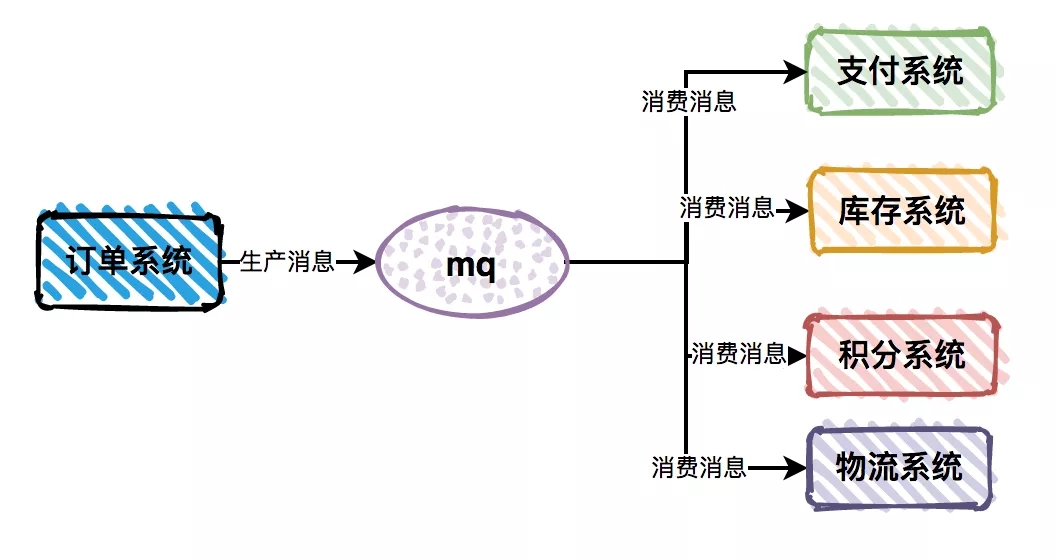
MQ 的机制需要生产者、MQ 服务器、消费者。有一定的学习成本,需要额外部署 MQ 服务器。
有些 MQ 功能非常强大、用法有点复杂,例如 RocketMQ。如果使用不好,会出现很多问题。有些问题,不像接口调用那么容易排查,从而导致系统的复杂度提升了。
4. 如何解决这些问题?
MQ 是一种趋势,总体来说对我们的系统是利大于弊的,难道因为它会出现一些问题,我们就不用它了?那么我们要如何解决这些问题呢?
4.1 重复消息问题
不管是由于生产者产生的重复消息,还是由于消费者导致的重复消息,我们都可以在消费者中解决这个问题。
这就要求消费者在做业务处理时,要做幂等设计。如果有不知道如何设计的朋友,可以参考“高并发下如何保证接口的幂等性?”,里面介绍得非常详细。
在这里我推荐增加一张消费消息表,来解决 MQ 的这类问题。
消费消息表中,使用 messageId 做唯一索引。在处理业务逻辑之前,先根据 messageId 查询一下该消息有没有处理过。如果已经处理过了则直接返回成功,如果没有处理过,则继续做业务处理。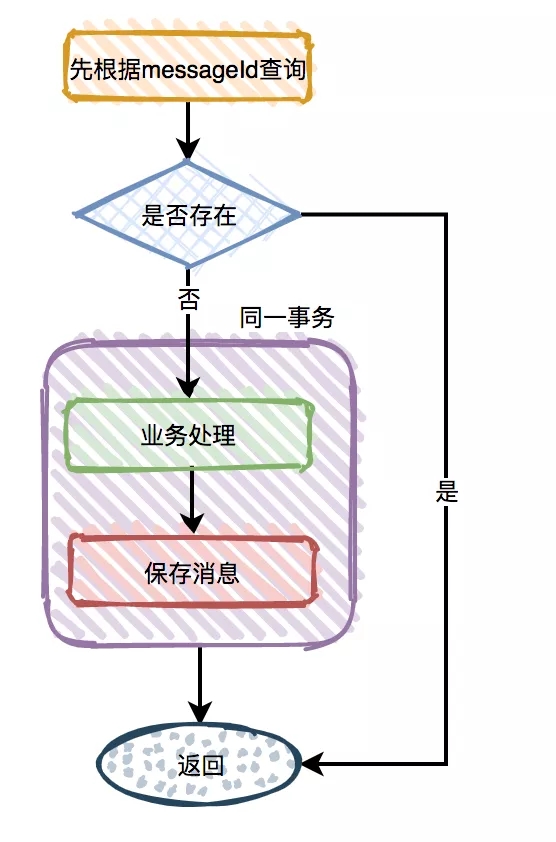
4.2 数据一致性问题
我们都知道数据一致性分为:
强一致性
弱一致性
最终一致性
而 MQ 为了性能考虑使用的是最终一致性,那么必定会出现数据不一致的问题。这类问题大概率是因为消费者读取消息后,业务逻辑处理失败导致的。这时候可以增加重试机制。
重试分为同步重试和异步重试。
有些消息量比较小的业务场景,可以采用同步重试。在消费消息时如果处理失败,立刻重试 3-5 次,如果还是失败则写入到记录表中。
但如果消息量比较大,则不建议使用这种方式。因为如果出现网络异常,可能会导致大量的消息不断重试,影响消息读取速度造成消息堆积。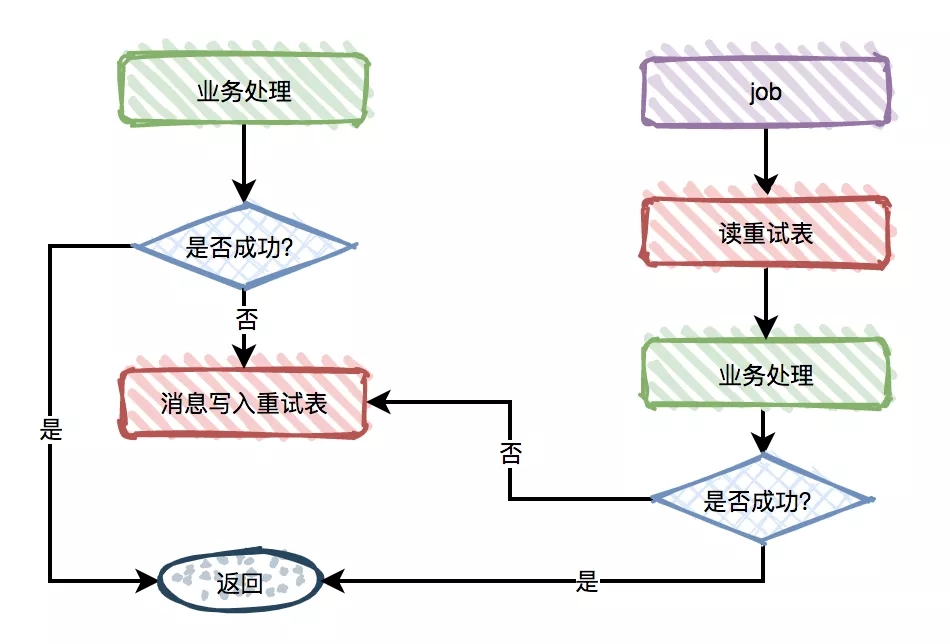
消息量比较大的业务场景,建议采用异步重试。在消费者处理失败之后,立刻写入重试表,有个 job 专门定时重试。
还有一种做法:如果消费失败,自己给同一个 topic 发一条消息。在后面的某个时间点,自己又会消费到那条消息,起到了重试的效果。如果对消息顺序要求不高的场景,可以使用这种方式。
4.3 消息丢失问题
不管你是否承认,有时候消息真的会丢。即使这种概率非常小,也会对业务有影响。生产者、MQ 服务器、消费者都有可能会导致消息丢失的问题。为了解决这个问题,我们可以增加一张消息发送表。
当生产者发完消息之后,会往该表中写入一条数据,状态 status 标记为待确认;
如果消费者读取消息之后,调用生产者的 API 更新该消息的 status 为已确认;
有个 job 每隔一段时间检查一次消息发送表,如果5分钟(这个时间可以根据实际情况来定)后还有状态是待确认的消息,则认为该消息已经丢失了,重新发条消息。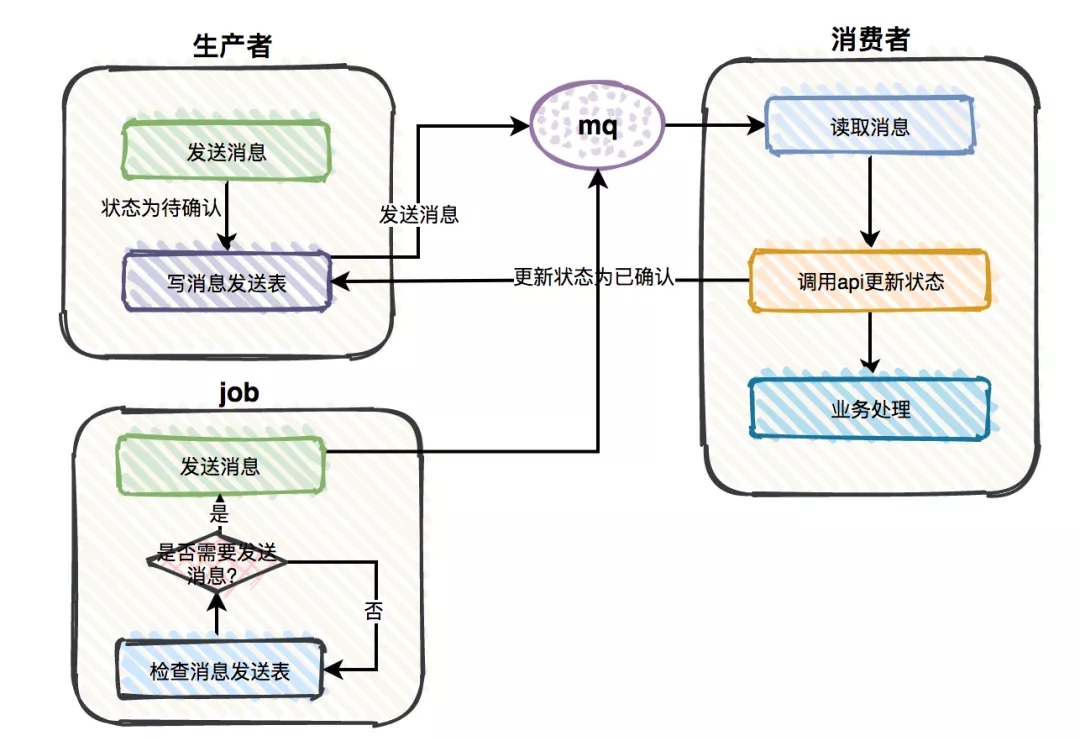
这样不管是由于生产者、MQ 服务器、还是消费者导致的消息丢失问题,job 都会重新发消息。
4.4 消息顺序问题
消息顺序问题是一种常见问题。我们以 Kafka 消费订单消息为例,订单有下单、支付、完成、退货等状态。这些状态是有先后顺序的,如果顺序错了会导致业务异常。
解决这类问题之前,我们需要先确认:消费者是否真的需要知道中间状态,只知道最终状态行不行?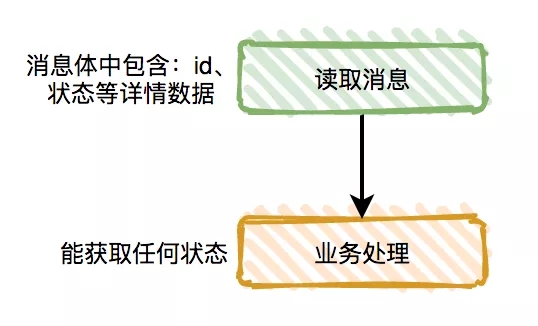
其实很多时候,我真的需要知道的是最终状态。这时可以把流程优化一下: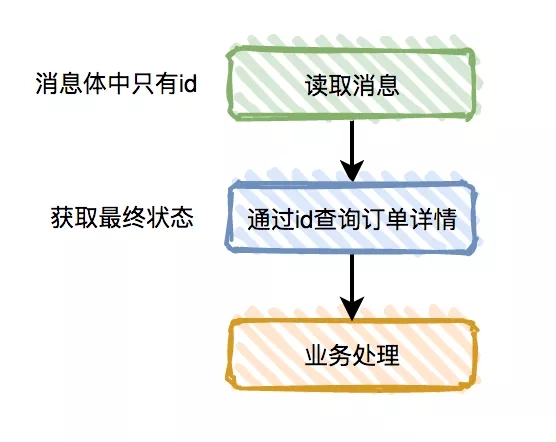
这种方式可以解决大部分的消息顺序问题。
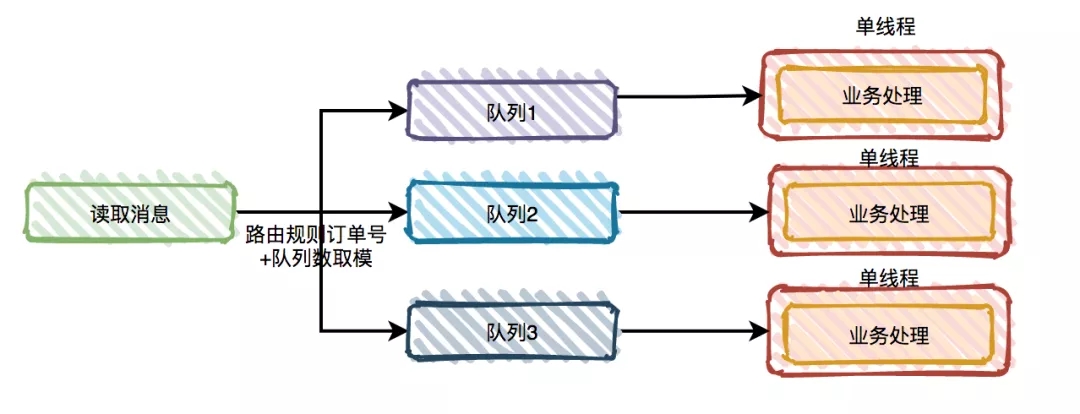
但如果真的有需要保证消息顺序的需求,那么可以将订单号路由到不同的 partition。同一个订单号的消息,每次到发到同一个 partition。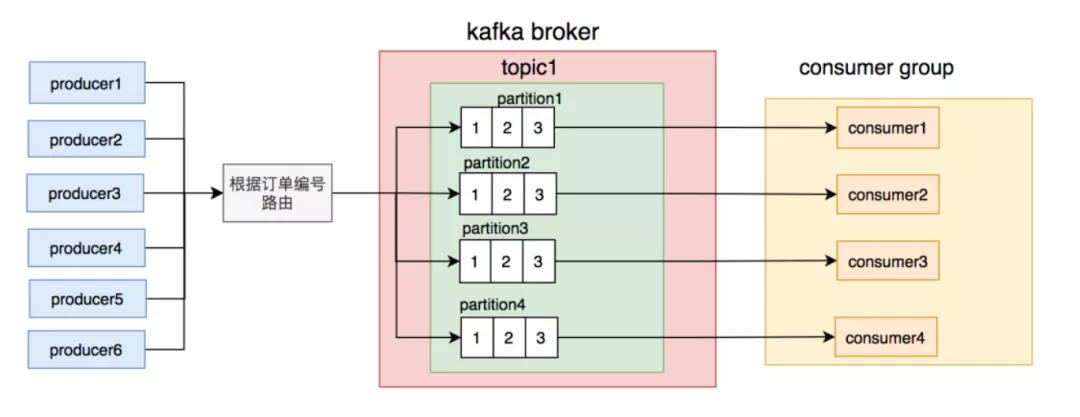
4.5 消息堆积
如果消费者消费消息的速度小于生产者生产消息的速度,将会出现消息堆积问题。其实这类问题产生的原因很多。如果想要进一步了解,可以看看“我用kafka两年踩过的一些非比寻常的坑”。
那么消息堆积问题该如何解决呢?这个要看消息是否需要保证顺序。
如果不需要保证顺序,可以读取消息之后用多线程处理业务逻辑。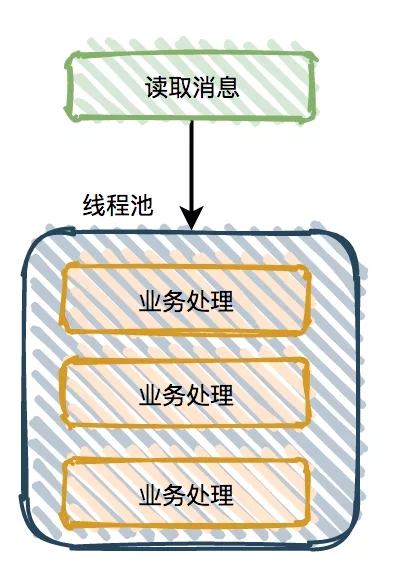
这样就能增加业务逻辑处理速度,解决消息堆积问题。但是线程池的核心线程数和最大线程数需要合理配置,不然可能会浪费系统资源。
如果需要保证顺序,可以读取消息之后将消息按照一定的规则分发到多个队列中,然后在队列中用单线程处理。